Automatizando Estratégias de Deployment com Ansible
- Por que deployment?
- Deploy != Release
- Tarefas, grupos e Ansible
- Estratégias de deployment
- Ansible e Pipeline de CI/CD
- Referências
Por que Deployment?
Ao descrever a stack tecnológica completa da sua aplicação, da camada mais baixa, até a mais alta: hardware, sistema operacional, middleware e aplicação - com as respectivas configurações desses elementos - é fácil perceber que quanto mais subimos nessa pilha, maior a frequência de mudanças. Seu hardware dificilmente vai mudar, seu sistema operacional possui um ciclo de vida longo, o seu middleware vai acompanhar necessidades pontuais da sua aplicação e novas versões desta estarão sendo implantadas com uma frequência maior que todos os itens anteriores, pois mesmo que seu ciclo de release sejo longo (meses), as aplicações serão os elementos mais voláteis dessa pilha.
Em “The Practice of System and Network Administration”, os autores categorizam os dois maiores “time sinkholes” - buraco que consome grande parte do seu tempo e pode ser causa de problemas futuros - em TI como: processo manual de instalação de Sistema Operacional e deployment.
Exemplos de problemas gerados pela execução manual para estes dois casos? Um dos servidores não teve o NTP configurado corretamente e a aplicação não funciona de forma adequada, pois utiliza algum “scheduler” ou de 5 servidores de um cluster, 1 deles está com a configuração divergente causando problemas em 20% das requisições.
No State of DevOps Report 2018, onde são apresentados estágios para evolução do DevOps, o Estágio 0 inclui práticas para automação de deployment de forma a reutilizá-lo entre sistemas e nos Estágio 1 e 2 o foco está em padronizar a pilha tecnológica e reduzir as inconsistências no seu ambiente. Bastante alinhado com o livro citado anteriormente.
Automação não apenas diminui o tempo gasto com atividades repetitivas, mas reduz consideravelmente a quantidade de atividades não planejadas (i.e unplanned work).
Por que não começar com instalação automatizada de Sistema Operacional então? Poderíamos, mas os resultados demorariam a aparecer, já que novos OS não são instalados com uma frequência tão alta e não ganharíamos tempo livre de imediato e talvez a iniciativa morra no meio do caminho.
Não convencido? Podemos também defender que entregas menores e frequentes são extremamente benéficas do ponto de vista das aplicações. Este trecho da minha apresentação sobre Testes de Infraestrutura no DevOpsDays BSB ‘17 ou basicamente qualquer livro dessa lista discorrem melhor sobre o tema.
Deploy != Release
A primeira coisa a entender é que embora deployment e release sejam utilizados de forma intercambiável, não significam a mesma coisa. Release consiste em liberar uma nova versão para o usuário, enquanto deployment é o processo técnico de implantar uma nova versão. Focaremos principalmente no processo técnico de deployment, como o título do artigo sugere.
Tarefas, Grupos e Ansible
Precisamos entender deployment de ponta a ponta, quais tarefas precisam ser realizadas, identificar grupos de servidores utilizados no processo, e os passos executáveis. E não cair em armadilhas descritas em “Automating the Unknown”.
Tarefas
Começando pelas tarefas, quais passos comumente são executados em um processo de deployment?
- Implantar aplicação/base de dados.
- Parar/iniciar serviços/monitoramento.
- Adicionar/remover servidor(es) do(s) balanceador(es) de carga.
- Verificações do estado da aplicação (readiness).
- Aprovação manual/humana?
Automatizar o processo de deployment e incluir uma etapa manual de aprovação é como andar de bicicleta de rodinhas para alguns, mas como me disseram uma vez: “Melhor andar de rodinhas do que não andar de jeito nenhum…“.
NOTA: E se alguma das ferramentas envolvidas não possuir uma API ou CLI para realizar tarefas de forma automatizada? Bom, talvez seja hora de pensar em trocar estas ferramentas, para cada um dos grupos de servidores envolvidos (servidores de aplicação, banco de dados, monitoramento e balanceador de carga) conheço várias ferramentas open source que possuem uma API ou CLI para que possamos executar tarefas de forma não assistida. É um excelente momento para adotar open source, no “Accelerate State of DevOps” produzido pelo DORA (DevOps Research and Assessment), o uso de open source é predominante em organizações de alto desempenho e a lógica é simples, projetos open source funcionam em um modelo darwinista, onde quem não se adapta morre (não tem base de usuários, não recebe contribuições e etc).
Grupos
Olhando para as tarefas é fácil identificar os grupos de servidores que iremos atuar:
- Implantar aplicação/base de dados.
- Parar/iniciar serviços/monitoramento.
- Adicionar/remover servidor(es) do(s) balanceador(es) de carga.
- Verificações da aplicação (readiness).
Playbook
Um processo de deployment tradicional, em alto nível, pode ser descrito da seguinte forma
- Parar monitoramento.
- Remover servidor do balanceamento de carga.
- Parar serviço.
- Implantar aplicação.
- Esperar aplicação ficar pronta para receber requisições.
- Executar operação reversa dos passos 3, 2, 1.
- Fazer o mesmo em N servidores.
Traduzindo o processo acima para um playbook Ansible teríamos para os passos de 1-5:
- name: Desabilita alertas
nagios:
action: disable_alerts
host: ""
services: webserver
delegate_to: ""
loop: ""
- name: Desabilita servidores no LB
haproxy:
host: ""
state: disabled
backend: app
delegate_to: ""
loop: " "
- name: Para serviço
service: name=httpd state=stopped
- name: Deploy
unarchive: src=app.tar.gz dest=/var/www/app
- name: Verifica aplicação
uri:
url: "http:///app/healthz"
status_code: 200
retries: 5
Por que Ansible?
Existem alternativas para realizar deployment de aplicações, mas o que torna o Ansible uma excelente opção?
- Orquestracão Multi-tier (delegate_to), ou seja, capacidade de atuar em diversos grupos de servidores (monitoramento, balanceador de carga, servidor de aplicação e etc) de forma ordenada.
- Rolling upgrade (serial): habilidade de controlar como as mudanças serão realizadas: 1 a 1, N a N, X%.
- Controle de erros (max_fail_percentage e any_errors_fatal): meu processo é tudo ou nada ou suporta falhas?
- Modules para:
- Monitoramento (nagios, zabbix e etc)
- Balanceadores de carga (haproxy, F5, Netscaler, cisco e etc)
- Services (service, command, file)
- Deployment (copy, unarchive)
- Verificação (command, uri)
Estratégias de deployment
Cada estratégia possui desafios e características e preciso equilibrá-las para escolher a mais apropriada. Vale também uma leitura sobre um conjunto de práticas para ter um Zero Downtime Deployment descritas do livro Release It!.
Rolling
O Rolling Deployment consiste em entregar de forma gradativa uma nova versão, e na prática, em Ansible, vamos fazer este controle com o serial.
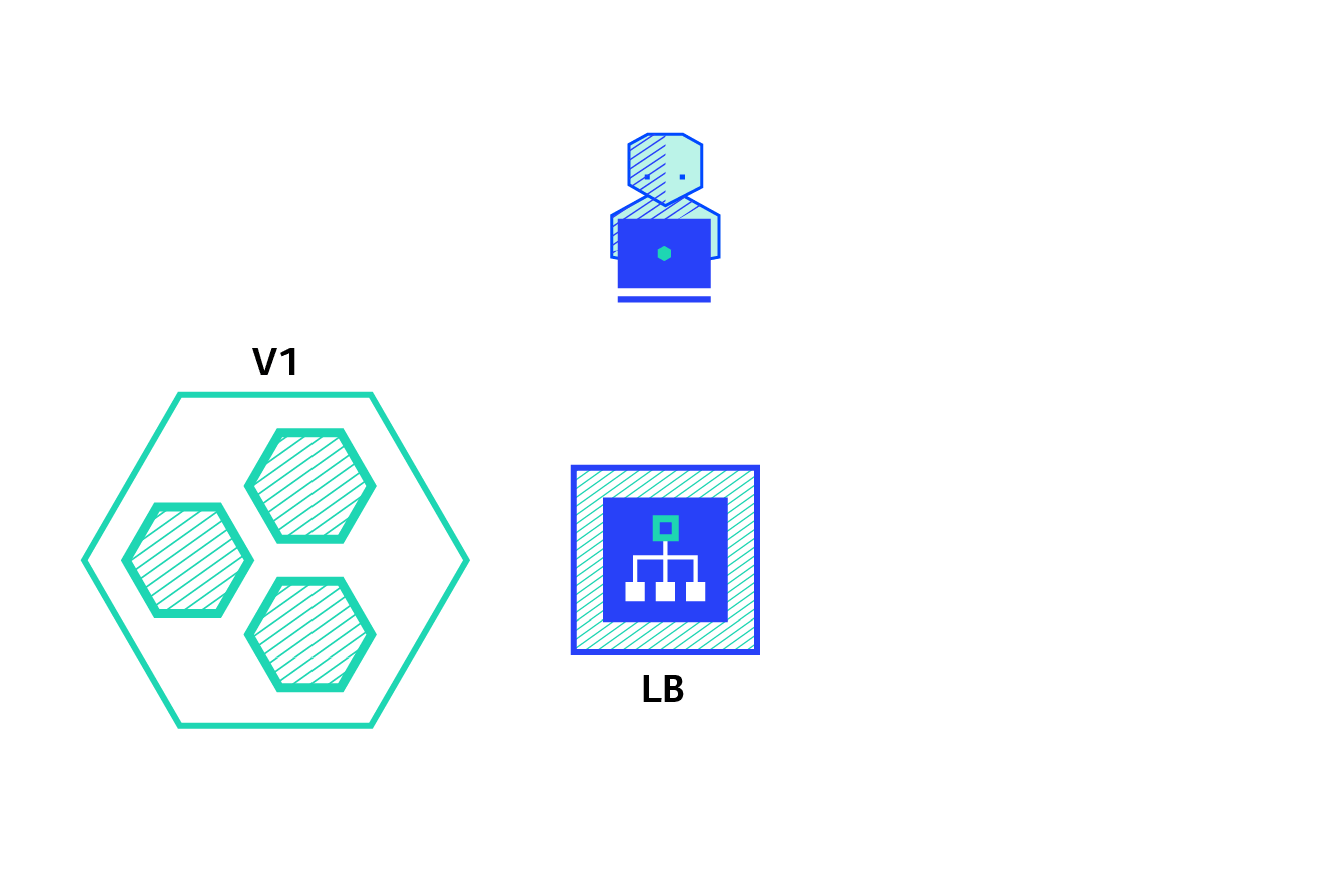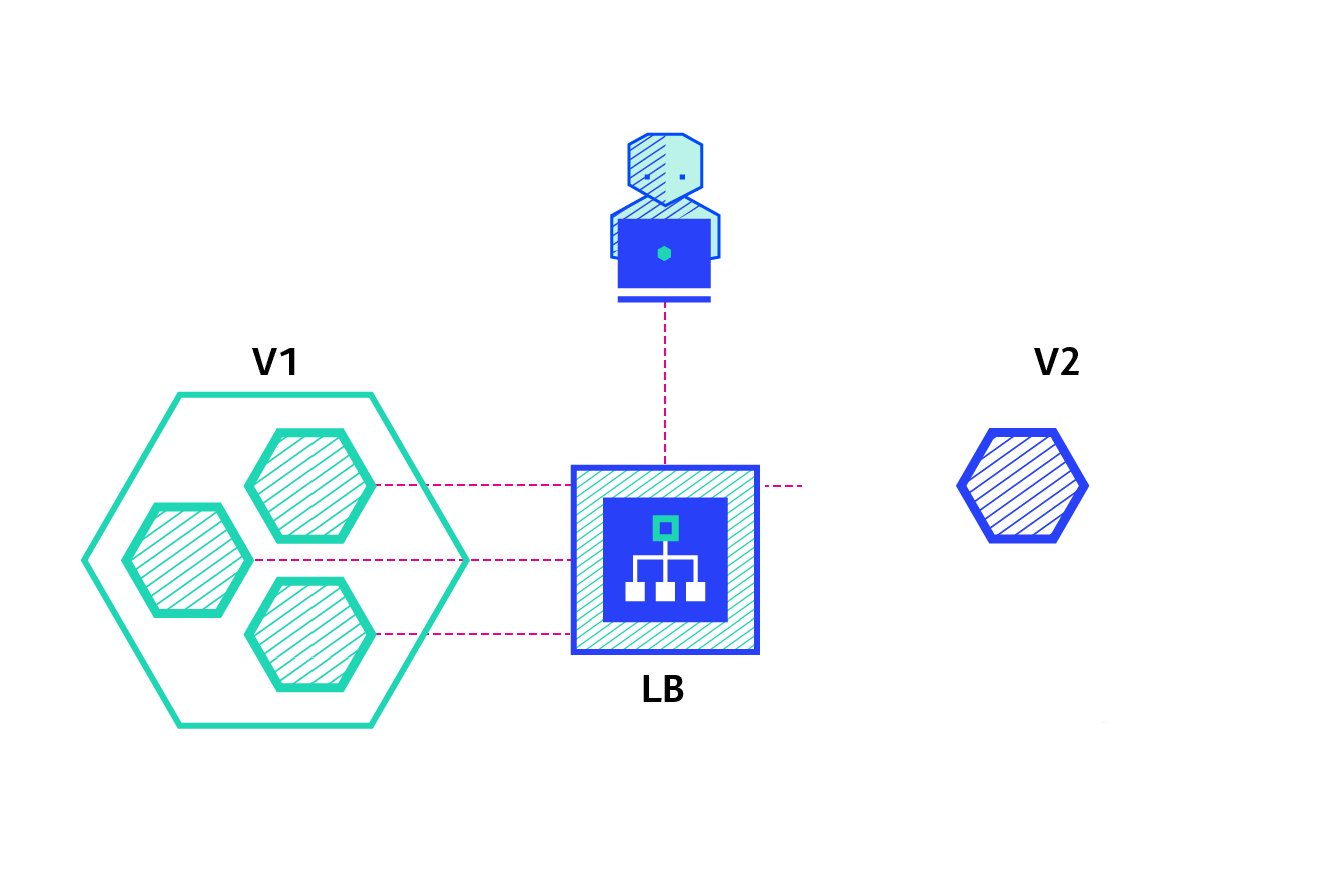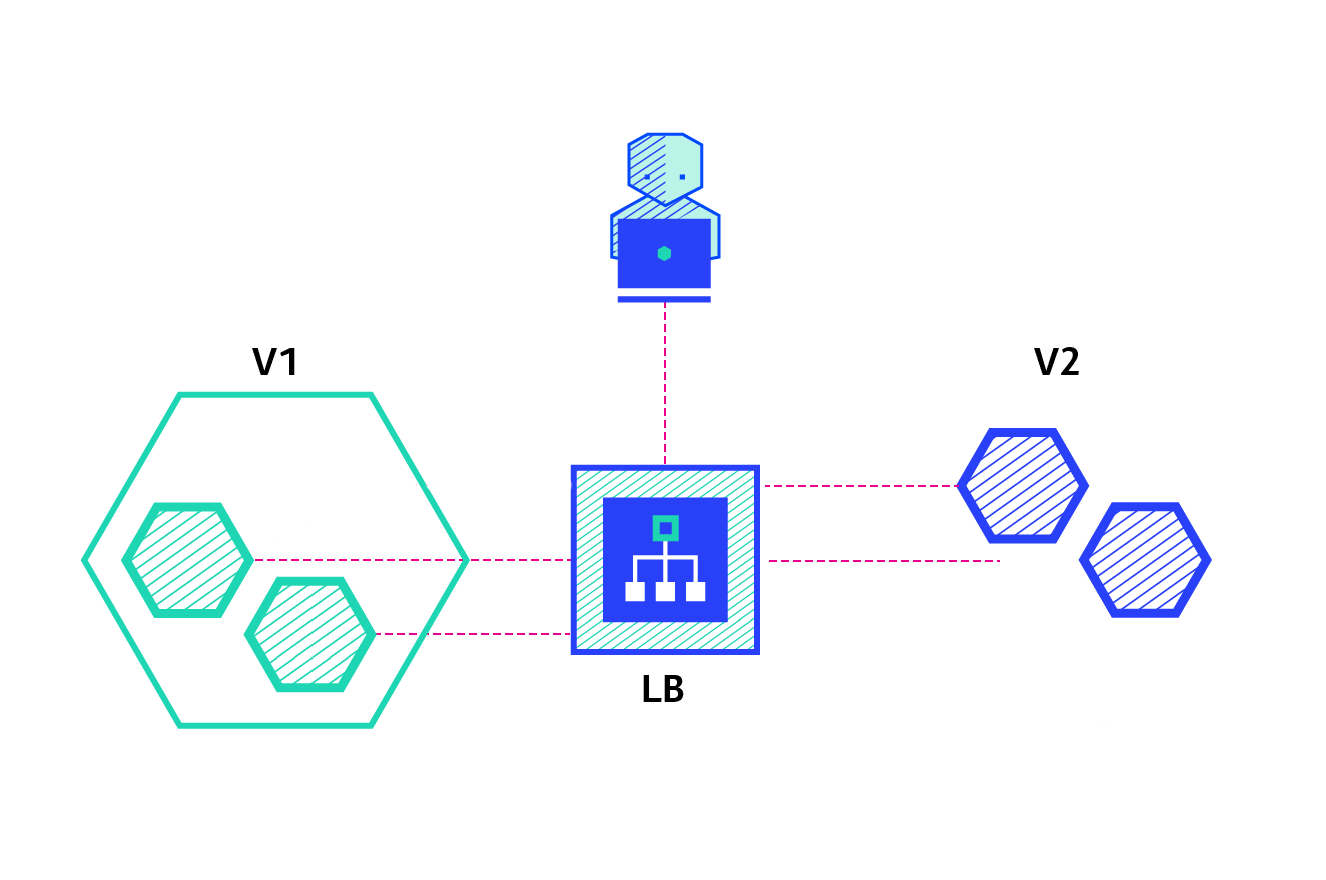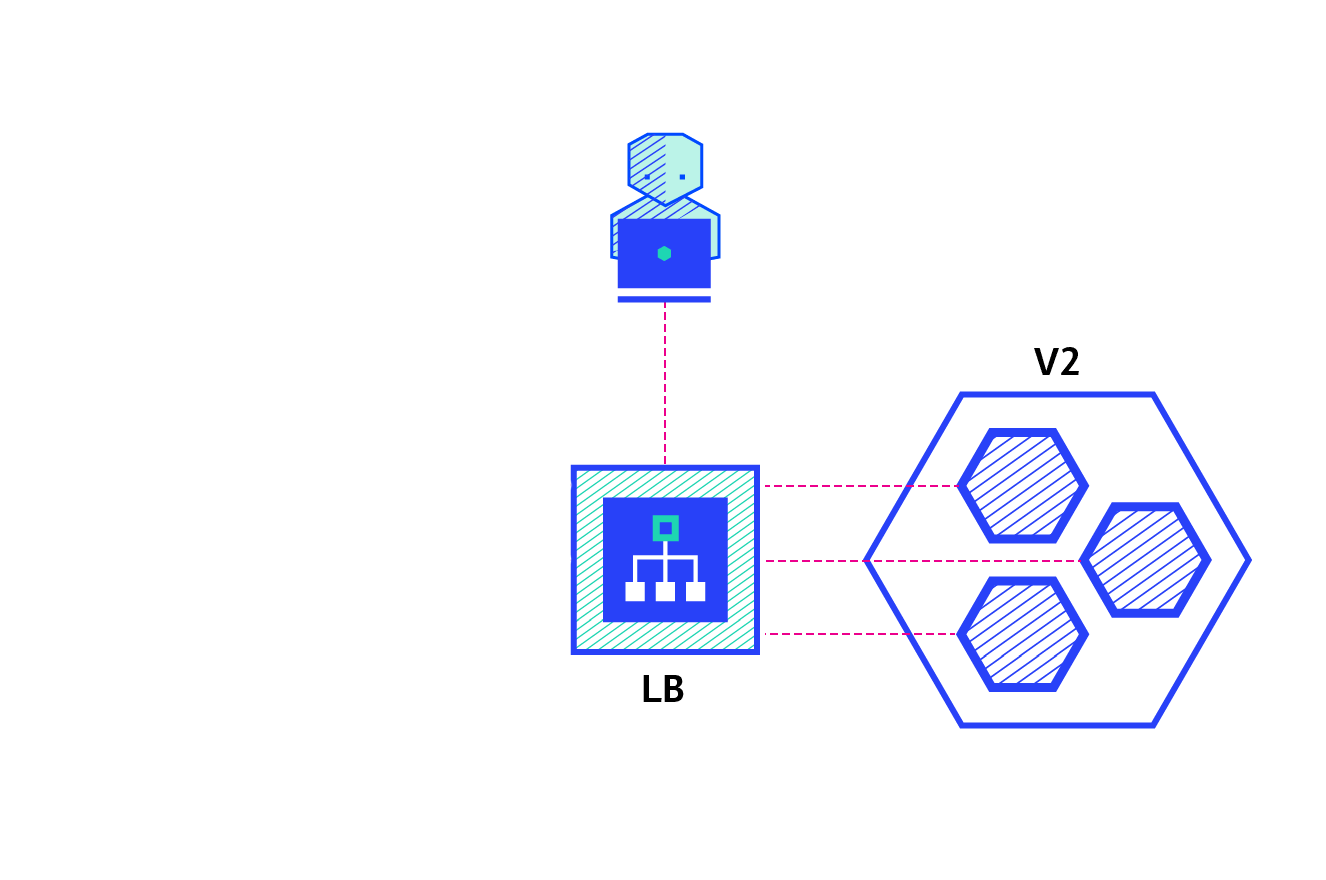
Quais as principais características dessa estratégia?
- É necessário construir uma estratégia de rollback automatizada (ou posso simples executar meu último Job (playbook e parâmetros) bem sucedido caso utilize o AWX/Tower).
- Servidores que apresentarem problemas podem ser deixados foram do monitoramento/balanceamento e corrigidos com calma posteriormente.
- Mais fácil de começar.
Exemplo de Rolling Deployment para uma aplicação rodando no Wildfly onde a mudança é realizada servidor a servidor:
- hosts: appserver
become: yes
become_user: wildfly
serial: 1
vars:
wildfly_home: /opt/wildfly
app_version: 1.5.0
checksum: fddd0f2320d79ad16a29b557e30fc94bba0ec4f3e51ee2377dd42d9ff0cfb78f
environment:
JAVA_HOME: /etc/alternatives/java_sdk/
PATH: "/bin:/bin:/usr/bin:/sbin"
pre_tasks:
- name: Check deployment content
command: "sha256sum /standalone/deployments/hawtio.war"
register: current_checksum
changed_when: False
- name: Stop instance in mcm
command: "jboss-cli.sh -c '/subsystem=modcluster:disable-context(virtualhost=default-host, context=/hawtio)'"
when: "current_checksum.stdout.split(' ')[0] != checksum"
tasks:
- name: Deploy app
get_url:
url: "http://central.maven.org/maven2/io/hawt/hawtio-web//hawtio-web-.war"
dest: "/standalone/deployments/hawtio.war"
mode: 0655
checksum: "sha256:"
notify:
- Wait for deployment
- Verify app
- Enable instance in mcm
handlers:
- name: Wait for deployment
pause:
seconds: 15
- name: Verify app
uri:
url: "http://:8080/hawtio"
status_code: 200
retries: 5
- name: Enable instance in mcm
command: "jboss-cli.sh -c '/subsystem=modcluster:enable-context(virtualhost=default-host, context=/hawtio)'"
Blue/Green
O Blue/Green Deployment consiste em ter, momentaneamente, a versão mais nova e uma versão anterior da aplicação.
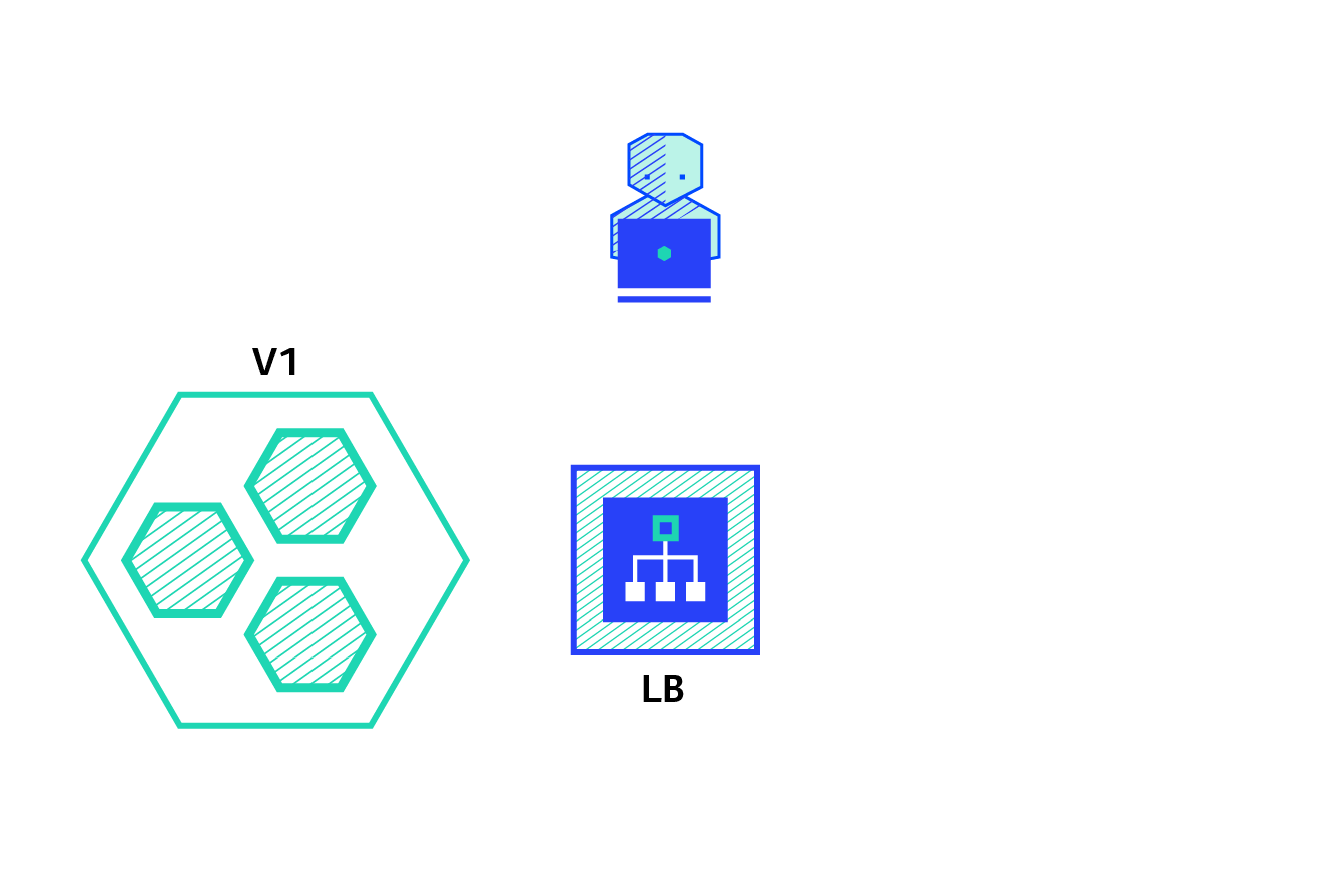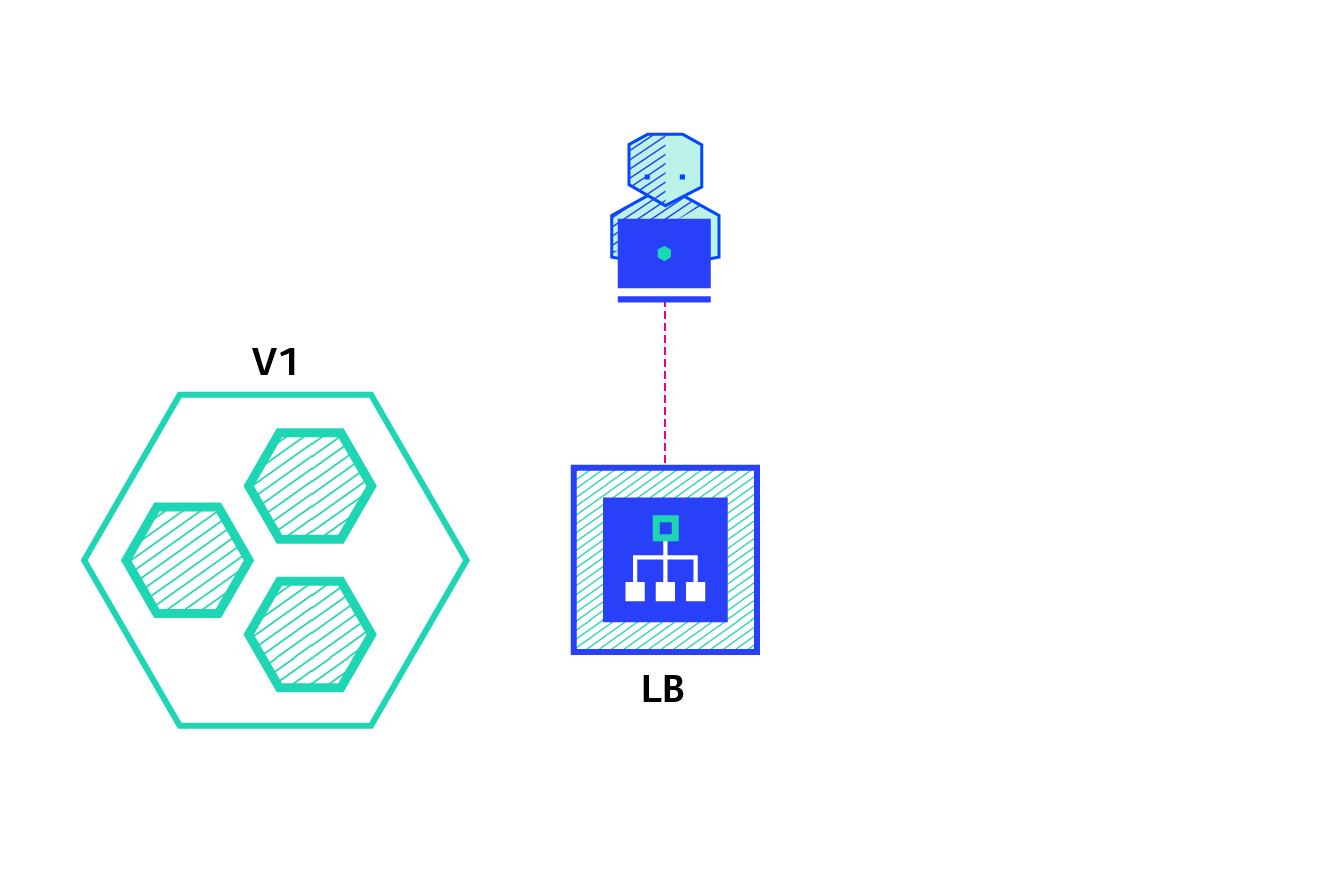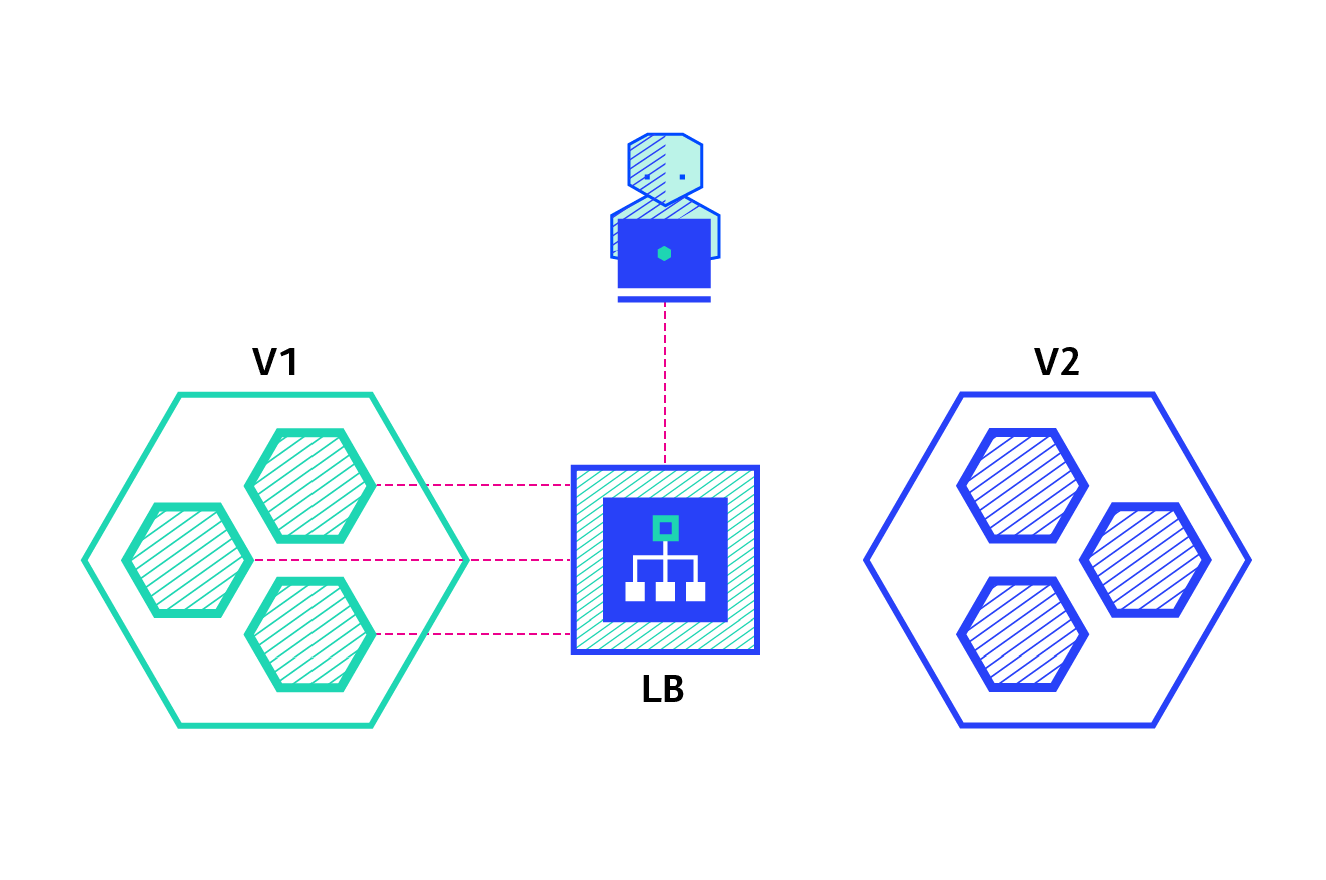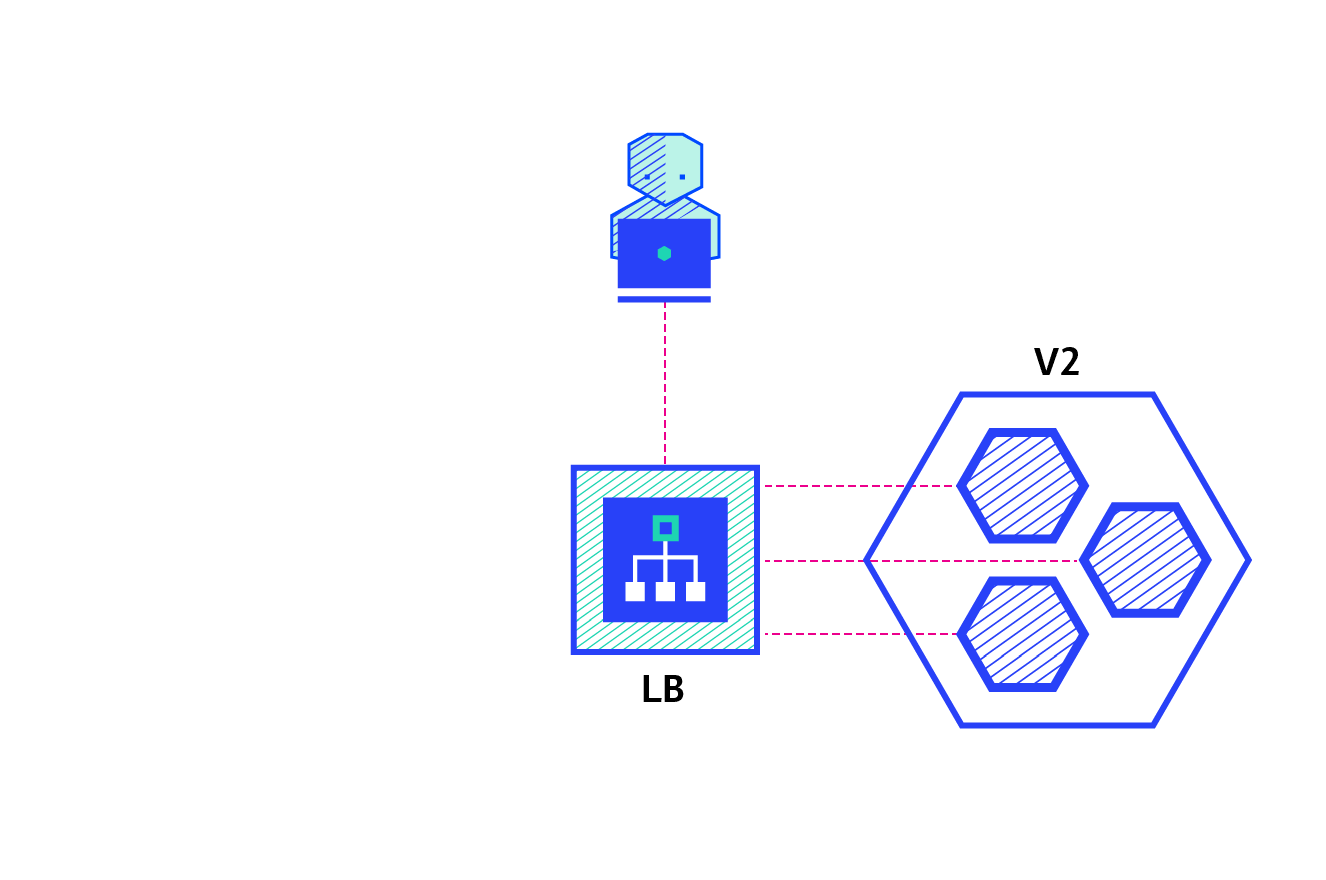
Características:
- Rollback instantâneo: uma mudança no load balancer.
- Fomenta uma prática conhecida como Phoenix Server.
Exemplo (Linguagem natural):
Blue:
- Provisionar nova instância.
- (Opcional) Configurar dependências da aplicação.
- (Opcional) Implantar aplicação.
- Ativar monitoramento.
- Fazer o mesmo N vezes.
Release:
- Mudar referência a servidores no load balancer.
Green:
- Desativar monitoramento.
- Destruir instância.
- Fazer o mesmo para todos servidores com versão antiga.
Ansible e Pipeline de CI/CD
Ansible é uma ferramenta de automação de propósitos gerais que permite provisionar infraestrutura, configurar servidores, appliances de rede e firewall
Enquanto bons servidor de Integração Contínua são eficientes em: obter código fonte de um SCM periodicamente - ou continuamente - utilizando credenciais, gerenciar diferentes versões de plataformas de desenvolvimento (Java, .NET, Ruby, Python), executar diferentes versões de ferramentas de build, disparar testes, migrations de base de dados, executar testes (unitários, integração, aceitação, desempenho)
Em um pipeline de CI/CD, todas estas atividades são necessárias e pode haver uma certa sobreposição. Mantenha-se com o que cada uma faz de melhor, entenda as limitações de cada uma e utilize a melhor ferramenta para o trabalho.
No pipeline exemplo abaixo para uma aplicação em Java, com Jenkins e Ansible, teríamos:
- Checkout Git (Jenkins)
- Build (Jenkins)
- Testes Unitários (Maven no Jenkins)
- Testes de Integração (Maven no Jenkins)
- (Opcional) preparar infraestrutura (nova ou existente) (Ansible)
- Deployment ambiente de testes manuais (Ansible)
- Database Migrations (Maven no Jenkins)
- Testes de aceitação (Jenkins e Selenium)
- (Opcional) preparar infraestrutura (nova ou existente) (Ansible) Testes de desempenho (Jenkins e JMeter)
- (Opcional) preparar infraestrutura (nova ou existente) (Ansible)
- Deployment homologacão e/ou produção (Ansible)
NOTA: Embora você possa utilizar o Ansible diretamente do seu servidor de Integracão Contínua, utilizá-lo para acionar a API do AWX/Tower deixa esse processo mais limpo, simples e reusável
Referências
Delegation, Rolling Updates, and Local Actions